关于Stable diffusion
Stable diffusion是一种基于潜在扩散模型(Latent Diffusion Models)的文本到图像生成模型,能够根据任意文本输入生成高质量、高分辨率、高逼真的图像。
– stable diffusion可以处理任意领域和主题的文本输入,并生成与之相符合的多样化和富有创意的图像。
– stable diffusion可以生成高达2048×2048或更高的分辨率的图像,并且保持了良好的视觉效果和真实感。
– stable diffusion还可以进行深度引导(Depth-guided)和结构保留(Structure-preserving)的图像转换和合成。例如,它可以根据输入图片推断出深度信息,并利用深度信息和文本条件生成新图片。
配置要求
注意:如电脑配置低于推荐配置,不建议强行安装。强行安装可能会出现一系列电脑报错问题。

使用教程
一、安装教程
1.一键安装完毕后,双击运行桌面快捷方式“SDWebUI一键端”运行。
2.进入软件界面后,点击右下角的一键启动。
3.成功出现下面的界面后,我们就可以正常使用Stable Diffusion了.
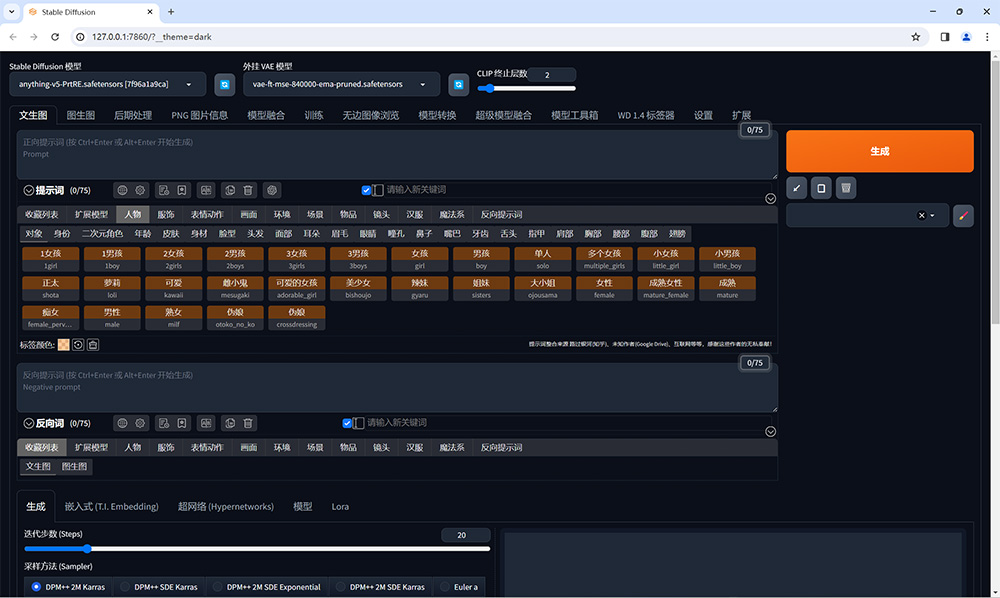
二、Stable Diffusion 基础操作
文生图
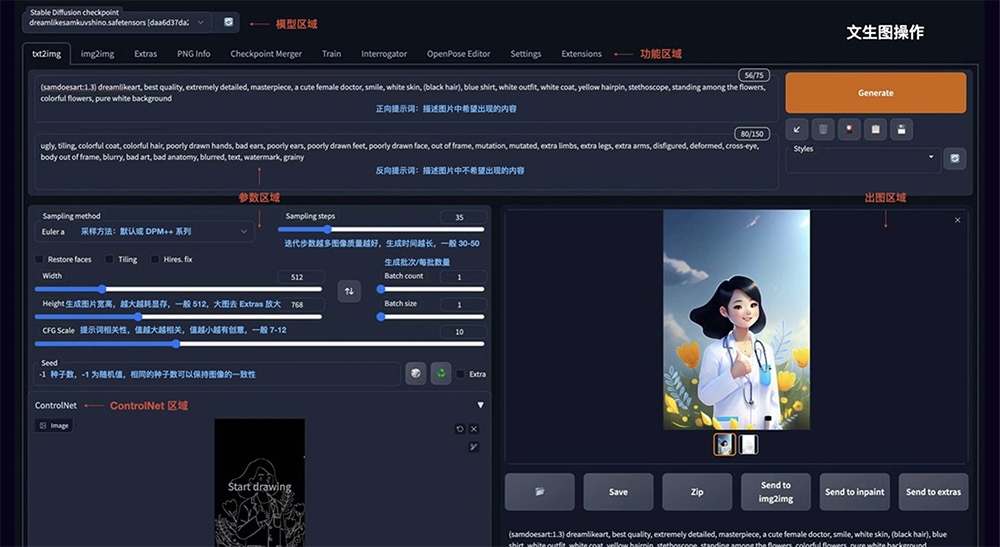
如图所示 Stable Diffusion WebUI 的操作界面主要分为:模型区域、功能区域、参数区域、出图区域。
1. txt2img 为文生图功能,重点参数介绍:
2. 正向提示词:描述图片中希望出现的内容
3. 反向提示词:描述图片中不希望出现的内容
4. Sampling method:采样方法,推荐选择 Euler a 或 DPM++ 系列,采样速度快
5. Sampling steps:迭代步数,数值越大图像质量越好,生成时间也越长,一般控制在 30-50 就能出效果
6. Restore faces:可以优化脸部生成
7. Width/Height:生成图片的宽高,越大越消耗显存,生成时间也越长,一般方图 512×512,竖图 512×768,需要更大尺寸,可以到 Extras 功能里进行等比高清放大
8. CFG:提示词相关性,数值越大越相关,数值越小越不相关,一般建议 7-12 区间
9. Batch count/Batch size:生成批次和每批数量,如果需要多图,可以调整下每批数量
10. Seed:种子数,-1 表示随机,相同的种子数可以保持图像的一致性,如果觉得一张图的结构不错,但对风格不满意,可以将种子数固定,再调整 prompt 生成
图生图
img2img 功能可以生成与原图相似构图色彩的画像,或者指定一部分内容进行变换。
可以重点使用 Inpaint 图像修补这个功能:
1. Resize mode:缩放模式,Just resize 只调整图片大小,如果输入与输出长宽比例不同,图片会被拉伸。Crop and resize 裁剪与调整大小,如果输入与输出长宽比例不同,会以图片中心向四周,将比例外的部分进行裁剪。Resize and fill 调整大小与填充,如果输入与输出分辨率不同,会以图片中心向四周,将比例内多余的部分进行填充
2. Mask blur:蒙版模糊度,值越大与原图边缘的过度越平滑,越小则边缘越锐利
3. Mask mode:蒙版模式,Inpaint masked 只重绘涂色部分,Inpaint not masked 重绘除了涂色的部分
4. Masked Content:蒙版内容,fill 用其他内容填充,original 在原来的基础上重绘
5. Inpaint area:重绘区域,Whole picture 整个图像区域,Only masked 只在蒙版区域
6. Denoising strength:重绘幅度,值越大越自由发挥,越小越和原图接近

ControlNet
安装完 ControlNet 后,在 txt2img 和 img2img 参数面板中均可以调用 ControlNet。
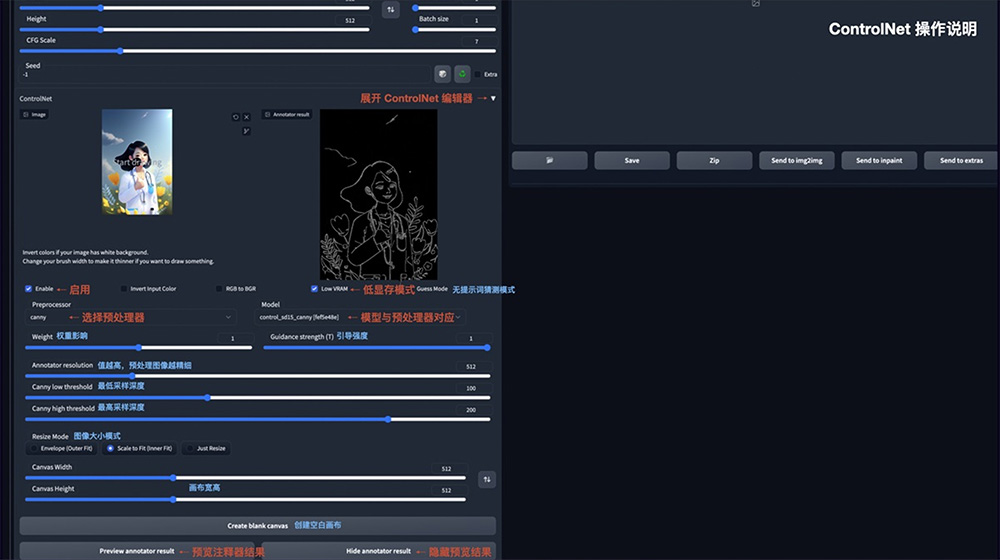
操作说明:
1. Enable:启用 ControlNet
2. Low VRAM:低显存模式优化,建议 8G 显存以下开启
3. Guess mode:猜测模式,可以不设置提示词,自动生成图片
4. Preprocessor:选择预处理器,主要有 OpenPose、Canny、HED、Scribble、Mlsd、Seg、Normal Map、Depth
5. Model:ControlNet 模型,模型选择要与预处理器对应
6. Weight:权重影响,使用 ControlNet 生成图片的权重占比影响
7. Guidance strength(T):引导强度,值为 1 时,代表每迭代 1 步就会被 ControlNet 引导 1 次
8. Annotator resolution:数值越高,预处理图像越精细
9. Canny low/high threshold:控制最低和最高采样深度
10. Resize mode:图像大小模式,默认选择缩放至合适
11. Canvas width/height:画布宽高
12. Create blank canvas:创建空白画布
13. Preview annotator result:预览注释器结果,得到一张 ControlNet 模型提取的特征图片
14. Hide annotator result:隐藏预览图像窗口
Prompt 语法技巧
文生图模型的精髓在于 Prompt 提示词,如何写好 Prompt 将直接影响图像的生成质量。
提示词结构化
Prompt 提示词可以分为 4 段式结构:画质画风 + 画面主体 + 画面细节 + 风格参考
1. 画面画风:主要是大模型或 LoRA 模型的 Tag、正向画质词、画作类型等
2. 画面主体:画面核心内容、主体人/事/物/景、主体特征/动作等
3. 画面细节:场景细节、人物细节、环境灯光、画面构图等
4. 风格参考:艺术风格、渲染器、Embedding Tag 等

提示词语法
1. 提示词排序:越前面的词汇越受 AI 重视,重要事物的提示词放前面
2. 增强/减弱:(提示词:权重数值),默认 1,大于 1 加强,低于 1 减弱。如 (doctor:1.3)
3. 混合:提示词 | 提示词,实现多个要素混合,如 [red|blue] hair 红蓝色头发混合
4. + 和 AND:用于连接短提示词,AND 两端要加空格
5. 分步渲染:[提示词 A:提示词 B:数值],先按提示词 A 生成,在设定的数值后朝提示词 B 变化。如[dog:cat:30] 前 30 步画狗后面的画猫,[dog:cat:0.9] 前面 90%画狗后面 10%画猫
6. 正向提示词:masterpiece, best quality 等画质词,用于提升画面质量
7. 反向提示词:nsfw, bad hands, missing fingers……, 用于不想在画面中出现的内容
8. Emoji:支持 emoji,如 ? 形容表情,? 修饰手

常用提示词举例

